Player Development: A Probabilistic Approach to Aging Curves
An introduction to Bayesian models in the context of the DEVe framework

Recently, we’ve discussed the DEVe framework which can be leveraged to evaluate the development trajectories of women’s hockey skaters.
An Introduction to Bayesian Thinking
In order to add flexibility to the predictions, I had incorporated a 90% confidence interval to the predictions of model M3 within the context of the frequentist approach.
The correct way of interpreting this 90% confidence interval is as follows: if we repeat this study 100 times for a given player, the “correct” value of her future N-WHKYe will be found in this range at least 90 times out of 100.
A common misconception regarding confidence intervals is that there is a 0.9 probability that the “true” N-WHKYe value for a player is comprised within the range. That interpretation of confidence intervals is erroneous.
However, from a player development standpoint, this probabilistic way of thinking could be interesting. That’s where the Bayesian approach comes into play.
In a Bayesian framework, we allow for N-WHKYe to potentially vary following the rules of a specific probability distribution.
Given the potential for variation of our predictions following probability distributions, the credible interval (which a Bayesian model yields) suits an intuitive probabilistic interpretation of the results.
In other words, if we are working with a 90% credible interval, we can say that there is a 0.9 probability that the future N-WHKYe value is comprised within the range.
Going back to the basics, Bayes’ theorem is the starting point for Bayesian probabilistic models.

It consists of several terms, which are explained below:
Prior = the probabilistic results we expect before seeing the results of our study.
Likelihood = the probabilistic results of our study.
Posterior = the probabilistic update of our prior (beliefs on the results) after seeing the data.
In short, Bayesians posit their prior belief on what the data looks like (prior) and after incorporating the data (likelihood), the posterior captures the updated belief following the exposition to the data.
N-WHKYe is a variable that is defined between 0 and +∞ and could take any value in this range (technically). In practice, however, N-WHKYe is usually defined in the 0 to Marie-Philip Poulin range in any given year. Kidding aside, this means that N-WHKYe is a continuous variable.
In order to use Bayes’ theorem with this type of variable, we have to leverage distributions that are continuous (that can take any value in a given range).
The interesting thing about continuous probability distributions is that we don’t calculate the probability that our variable is equal to a specific N-WHKYe value (because that probability is always equal to 0). We instead calculate the probability that our variable is in a specific N-WHKYe range.
And as we mentioned above, analyzing ranges is an elegant way of capturing or approximating the uncertainty revolving development environments.
A Bayesian Example with N-WHKYe
The math to apply Bayes’ theorem with continuous distributions is fairly complex. There is, however, a way to simplify it when applying it in specific situations.
This is when distributions are conjugate. Conjugacy is basically present in a Bayesian framework when the prior and the posterior distributions are of the same family.
The simplest case of conjugacy with continuous variables is the Normal-Normal example. In this case, the prior, likelihood and posterior distributions are all Normal.
As a reminder, normal distributions are characterized by a bell-shaped probability density function (pdf). Normal distributions have two parameters, a mean (μ) and a standard deviation (σ). Here is the symmetrical bell-shaped pdf with μ = 0 and σ = 1:

We can take the example of Alina Müller’s projected N-WHKYe to illustrate Bayesian modelling within the DEVe framework.
This season, Alina Müller put up an N-WHKYe of 0.86 in the NCAA. For next year’s N-WHKYe, let’s assume that it is normally distributed, with mean μ and standard deviation σ (with variance σ²).
When looking at the historical results of forwards who put up over 0.85 in a given year, future N-WHKYe for these players can be approximated by the following normal distribution N(ν, τ) = N(0.70, 0.26). We can consider this to be our guess for Alina Müller’s future stats before looking at her data (i.e., this is our prior).
Last week, when analyzing the error term of N-WHKYe, we noted that the “standard” deviation of future N-WHKYe for players having put up over 0.85 the previous year was σ = 0.31. Therefore, we will use 0.31 as the standard deviation for our likelihood with unknown mean μ.
Furthermore, simulating model M3 with n=10 times, using different hyper-parameters each time, yields an average of x̄ = 0.57. These are our experimental results (i.e., our data).
When using the Normal-Normal conjugacy, the posterior distribution has the following two parameters (proof):
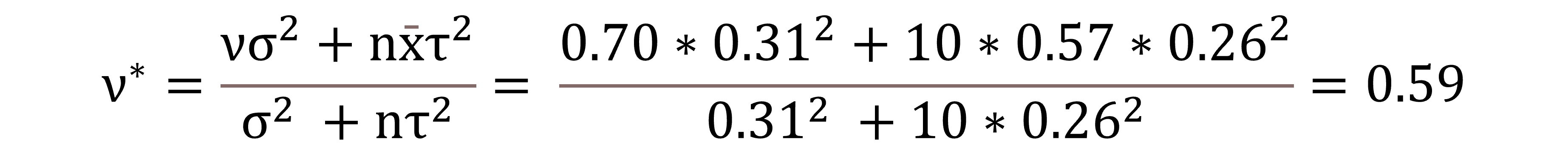

The posterior distribution of Alina Müller’s N-WHKYe for next year can be approximated by a normal distribution of mean ν* = 0.59 and standard deviation τ* = 0.09. Below is shown the pdf for our posterior distribution:

From this distribution, we can derive the following insights:
Probability that A. Müller puts up above 0.59 N-WHKYe next year = P(X ≥ 0.59) = 0.50
Probability that A. Müller puts up above 0.65 N-WHKYe next year = P(X ≥ 0.65) = 0.25
Probability that A. Müller puts up above 0.75 N-WHKYe next year = P(X ≥ 0.75) = 0.04
But this model, which serves as an introduction to Bayesian thinking, still highly relies on our frequentist model. That is why it is technically still predicting probable downward trending stats for Alina Müller.
Next week, we will build a Bayesian model to generalize probabilistic predictions within the DEVe framework.